
「RAGって何?」最近よく聞くAI用語の正体
RAGは「Retrieval-Augmented Generation」の略です。
日本語では「検索拡張生成」と呼ばれ、大規模言語モデル(LLM)による言語生成に加えて外部情報を検索に組み込むことでユーザーが求めている回答の精度を高める技術のことです。
なぜ今、RAGが注目されているのか
最近ではChatGPT-4oやClaude 3.5 SonnetなどのLLMでも高い回答精度でユーザー満足度が高まっています。
一方でLLMでは学習されていない最新の情報や限られた環境でしか使われない専門用語には対応できていないなどのデメリットがあります。
RAGはLLM単体での利用では生じてしまうデメリットを外部情報からも検索することで解決することができます。
例えば外部情報には専門性の高い情報を保存することで専門家レベルの回答を生成することが可能となり、外部情報を持つデータベースを定期的に更新して常に最新の知識を蓄えることで専門性と情報鮮度の正確性が得られます。
このようにして、「大規模言語モデル(LLM)」とカスタマイズ可能な「外部情報」から検索して、回答を生成することでニーズに適した検索システムを活用することが可能となります。
RAGの簡単な仕組み
「RAG」という名称はそれぞれの特徴としている機能の頭文字から成り立っています。
Retrieval(検索): 必要な情報を探す
ユーザーが求めているデータを大規模なデータベースから探し出す過程を指します。
入力されたキーワードやセマンティック検索を用いて関連性の高いデータを抽出します。
Augmented(拡張): 見つけた情報を追加
拡張とは外部のデータベースやウェブサイトから最新の情報を取得することでLLMのモデルとは別の新しい知識や最新の情報を取得して次の生成プロセスに組み込むことを指します。
Generation(生成): 回答を作成
検索と拡張によって得られた情報を基にユーザーからの質問に対する回答を生成する過程を指します。
「RAGの動作原理」: 質問から回答までの流れ
LLMでRAGを使用する場合の概念的なフローは次のようになります。
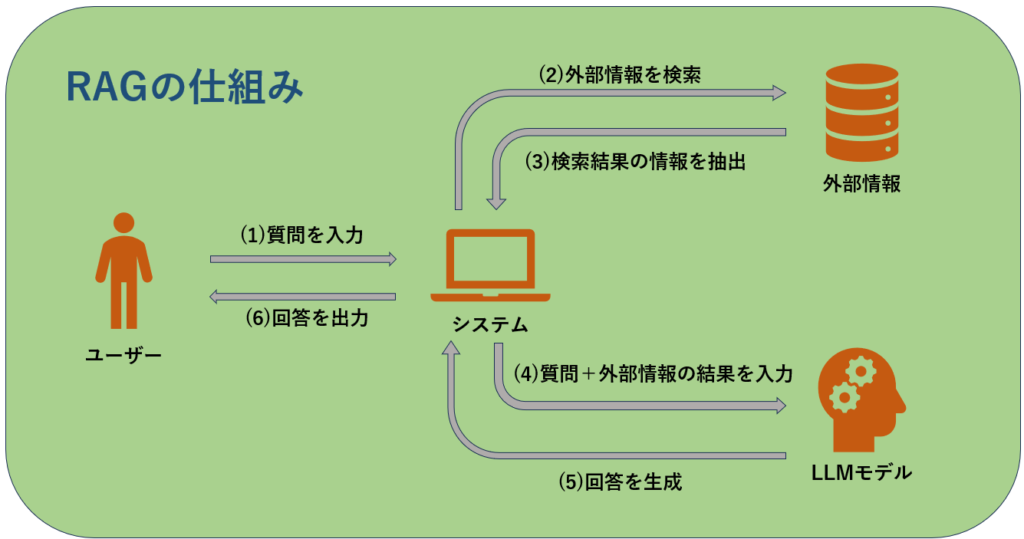
この6つのフローも大きく2つのフェーズに分けて理解することができます。
(1)~(3)までが検索フェーズ(Retrieval Phase)
(4)~(6)までが生成フェーズ(Generation Phase)
ユーザーが回答を得たとして、正しいくて精度の高いものにするためにはそれぞれのフェーズで対策が重要になってきます。
検索フェーズの場合は外部情報のデータベースなどに最新で正しいデータを追加や検索しやすいようにフォーマットの整形、
生成フェーズの場合は出力結果を読みやすいものにするためにプロンプトの工夫やデータ追加によるモデルの再トレーニングがあげられます。
RAGの主な特徴による
リアルタイムでの最新情報の統合
RAGの中で最も革新的な特徴となっているのが外部情報の活用による回答取得の精度向上です。
- 更新頻度が高いデータベース
- ニュースサイトなどのWeb検索
- API連携を用いた外部サービスなど
上記の拡張データを組み込むことでユーザーが求めている回答をリアルタイムで取得することが可能となります。
従来の静的なAIモデルでは難しかった最新情報への即時アクセスが可能となり、より正確で時宜を得た回答を提供できるようになりました。
回答の透明性向上による「ブラックボックス問題」への対応
AIの「ブラックボックス問題」とは、AIの意思決定プロセスが不透明なことで人間が理解・検証しづらいという欠点がありました。
提示する回答に根拠がないことや誤りが含まれていることに対して利用する上で人間が気づかないという問題があります。
つまり、「人間にはAIがどのような思考のもとで回答を導きだしているかわからない」という問題があります。
RAGによる透明性の向上によって「ブラックボックス問題」への対応が可能となります。
- 回答生成に使用された具体的な情報源の明示
回答の根拠が明確になることで、AIの判断に対する説明が容易になります。 - 使用されたキーワードや検索アルゴリズムの詳細を表示
使用されたキーワードや検索アルゴリズムの詳細を表示されます。
AIの判断過程が透明化されることで、責任所在の明確にすることができます。 - 情報の選択基準の説明
なぜその特定の情報が選ばれたかの理由を提供します。
例えば、回答の各部分に対する確信度を数値やグラフで表示することで信頼性が高まります。
RAGとChatGPTの違い
RAGとChatGPTは、それぞれに長所と短所があり、用途に応じて適切な技術を選択することが重要です。
RAGは最新性と透明性に優れ、専門的で正確な情報提供が求められる分野で特に有効です。
ChatGPTは汎用的な対話や創造的なタスクに強みを発揮します。
- 知識ベースの性質
RAG:動的に外部情報を利用してリアルタイムで最新情報にアクセスが可能
GPT:静的な事前学習データに基づいて回答を生成 - カスタマイズ性
RAG:知識ベースの変更だけで容易にカスタイマイズが可能
GPT:モデル全体の大学習やファインチューニングが必要 - 処理速度とリソース要求
RAG:外部情報への検索に時間がかかる場合があるが、モデル自体は比較的小規模でも高性能な回答が可能
GPT:一度学習すれば高速に回答取得が可能だが、大規模なモデルサイズによるハードウェア要求が高い - 応用分野
RAG:一般的な会話、創造的なタスク、テキスト生成に強い
GPT:最新情報や専門知識を要する分野に適している
まとめ
RAGは、生成AIモデルが外部情報を活用することで、より精度の高い応答を提供する画期的な技術です。その主な特徴には、外部データとの高度な知識統合、リアルタイムでの最新情報の反映、そしてユーザーに合わせたパーソナライズドな応答生成が挙げられます。これにより、従来の生成モデルが抱えていた限界を突破し、幅広い用途で活用が進んでいます。
しかし、外部データの信頼性やリアルタイム性、ブラックボックス問題などの課題も抱えています。
将来的には、より高度なパーソナライゼーションや透明性の向上が期待され、RAGの応用範囲はますます広がりそうです。
