
Sudachiとは
Sudachiはオープンソースの形態素解析エンジンのひとつで形態素解析や分かち書きの処理が行えます。
Sudachiを開発した研究所が徳島にあるのでSudachiとなったのでしょうか。
MeCabにSudachiにCabochaと、、、
食べ物にまつわるのがお決まりっぽいですね。
以前はMeCabを入れてみたので、今回はSudachiを使って形態素解析をしてみます。
MeCabの導入方法、MeCab辞書のNEologdの導入方法もまとめています。
SudachiPy
今回はSudachiをインストールしてPythonで使うためにSudachiPyを入れます。
公式のGitHubを見て進めれば大丈夫ですが、備忘録としてこちらにも記載しています。
https://github.com/WorksApplications/SudachiPy/blob/develop/docs/tutorial.md
SudachiPyの導入手順
SudachiPyのインストール
仮想環境に入ったらSudachiPyをインストールします。
pip install sudachipy辞書のインストール
次に辞書をインストールします。
辞書はsmall, core, fullの3種類あるますが、まずはcoreを入れて進めてみます。
pip install sudachidict_coreインストールが完了したら、あとはPythonファイルを作成して動かしていきます。
sudachi.pyの作成
公式のGitHubに載せているコードをそのまま張り付けて動かしてみます。
from sudachipy import tokenizer
from sudachipy import dictionary
tokenizer_obj = dictionary.Dictionary().create()
# 複数粒度分割
mode = tokenizer.Tokenizer.SplitMode.C
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# => ['国家公務員']
mode = tokenizer.Tokenizer.SplitMode.B
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# => ['国家', '公務員']
mode = tokenizer.Tokenizer.SplitMode.A
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# => ['国家', '公務', '員']実行して確認してみます。
動かしてみるとコメントアウトされている内容が表示されました
python sudachi.py run
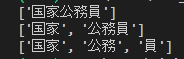
なるほど、単語ごとに区切られていますね。
MeCabのNEologdインストール時に検証した文章で試してみます!
「鬼滅の刃は週刊少年ジャンプの看板作品だったが、今では呪術廻戦が人気だ!」

画像が小さいので、ひとつ抜き出してみました。こうなっています。
['鬼', '滅', 'の', '刃', 'は', '週刊', '少年', 'ジャンプ', 'の', '看板', '作品', 'だっ', 'た', 'が', '、', '今', 'で', 'は', '呪術', '廻', '戦', 'が', '人気', 'だ', '!']MeCabの時とほとんど一緒で、NEologdのほうが精度が良いですね。
NEologdでは「鬼滅の刃」「呪術廻戦」「週刊少年ジャンプ」が一単語になっていました。
では次の手を打ってみます。
SudachiDict-fullのインストール
さっきはsudachidict_coreをインストールしていたので、デフォルトの状態でした。
fullにしてみたは精度がよくなるのでは?と思ったのでこちらで試してみます。
pip install SudachiDict-full
sudachi.pyの更新
coreはデフォルトの状態だったので、辞書をfullに指定します。
品詞なども確認したいのでコードを追加しています。
from sudachipy import tokenizer
from sudachipy import dictionary
tokenizer_obj = dictionary.Dictionary(dict_type="full").create()
mode = tokenizer.Tokenizer.SplitMode.C
sample_text= "鬼滅の刃は週刊少年ジャンプの看板作品だったが、今では呪術廻戦が人気だ!"
tokens = tokenizer_obj.tokenize(sample_text, mode)
print(tokens)
array = []
for t in tokens:
array = t.surface(),t.part_of_speech(),t.reading_form(),t.normalized_form()
print(array)PythonでSudachiを動かしてみる
更新ができたら、再度実行してみます!
Python sudachi.py run
分かち書きで見ても、精度が上がっていますね!
「呪術廻戦」はダメでしたが、「鬼滅の刃」「週刊少年ジャンプ」は一単語として認識されています!
['鬼滅の刃', 'は', '週刊少年ジャンプ', 'の', '看板', '作品', 'だっ', 'た', 'が', '、', '今', 'で', 'は', '呪術', '廻', '戦', 'が', '人気', 'だ', '!']coreではなく、fullを最初から使うのでよさそうですね。

